Solr 5 puzzle: Magic date – answer (part 2)
(This is the final part of the explanation for the Solr puzzle that brings together schemaless mode, dates and other automagical parts of Solr. See the puzzle post for the setup and the 1st part of the answer for explanations of why 3 out of 5 answer choices were not valid)
By now, we are facing a basic binary choice. In summary, given a schemaless configuration, we indexed a new field today with a value 2016-04-18, which got parsed as a date 2016-04-08T00:00:00Z. We now want to search with the query Fri and see whether or not that record matches.
There are two ways to look at it, forward and backward. We will look at this backward from the search:
What do we actually search here? It is not a field today, which did not exist at the start of the puzzle. Instead, we are searching a default field.
What’s our default field? Well, it is not defined explicitly in our query with a df parameter, so it must be in definition for the /select handler. Which starts at line 773 for the Solr 5.5 distribution. Except it is not there either, but in the initParams section on line 853. Finally, we find out that we are searching the field _text_. We could also have discovered this by using echoParams=all in our query, such as (escaping the & symbols for Unix command lines):
So, why did we not see _text_ field and what is its content? The first one is a bit easier to answer. If you look in the original managed-schema file on line 123 (line ~401 in your own rewritten post-today schema file) , you can see that the field is defined multiValued/indexed/NOT-stored. Since it is not stored, it does not display when we run a query, but it is indexed. And right on the next line 124, we can see the copyField statement that copies content of ALL the fields to the _text_. This would include the field today after it gets created.
You can also discover the same field definition and copyField information in the Schema Browser screen of the Admin UI. More importantly, on the same screen you can Load Term Info for the field and see what indexed tokens it contains. Even if the field is not stored, we can look at its content without resorting to something like Luke.
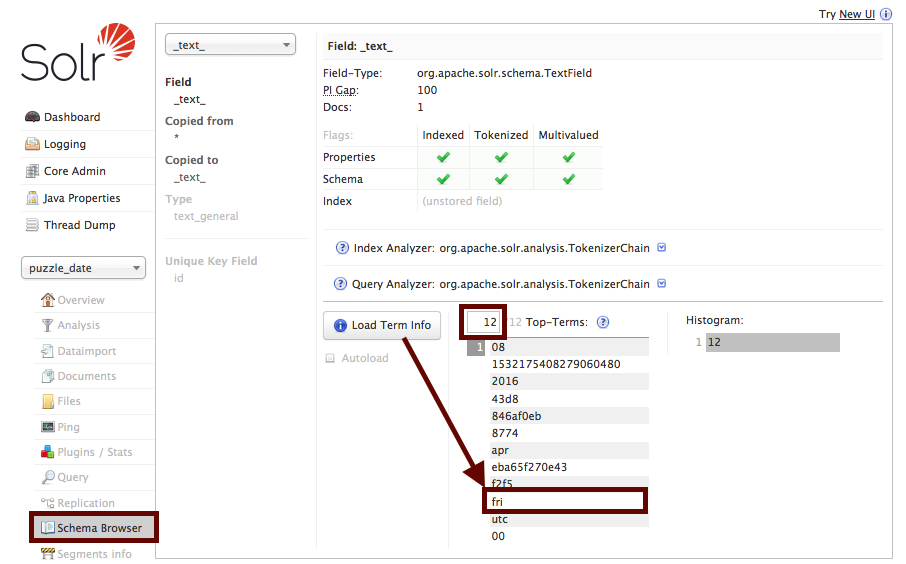{kind=link}
And suddenly, we can see the term Fri showing up in the _text_ field. Which means we can search for it and our single record will show up. Making the answer choice 5 - the correct one.
But where did that token came from? Well, 8 April 2016 happens to be a Friday, but that does not explain how it gets there. Let’s make this a tiny bit simpler by making this invisible content easier. We can do it by redefining _text_ as stored and rerunning the indexing, but instead we will just add another copyField instruction.
For this, we need to switch to the new Admin UI, which provides new buttons to control managed schemas in its version of the Schema (browser) screen. Let’s add a copyField from all fields to a field text_ss. (If you don’t know why this would work, I am leaving it as a home work 🙂 ).
Now, we need to reindex, so let’s rerun the indexing command again:
Now, if you rerun the search, one of the two records should now include the field text_ss, with several values, including Fri Apr 08 00:00:00 UTC 2016. (Are you surprised about having two records? If so, reread the first part of the answer even more carefully.)
So, we know where the Fri came from in the _text_ field and therefore why we get the record match during the search. But now we have THREE different date format between what we indexed, what we displayed and what we actually searched. Why?
For that, we have to go back to the schemaless mode magic and understand it at the level below one big black-box UpdateRequestProcessor chain.
Let’s look again starting from the line 1316 of the solrconfig.xml. The date value mapping actually happens in two steps. First, we detect and parse text value as a date with the ParseDateFieldUpdateProcessorFactory on the lines 1330-1350. That mutates the text value into the java.util.Date, as per the parser’s documentation. At this point, we have lost our original string representation and are actually carrying a different object type around.
The next step is AddSchemaFieldsUpdateProcessorFactory, which looks at those object types and maps them to field types. Specifically, on lines 1357-1360, we map all new fields carrying an object of type java.util.Date to a type tdates , which is configured as TrieDateField. TrieDateField knows what to do with a java.util.Date, so we are all done.
Except, we don’t care what TrieDateField is doing in our curveball. We are looking at the copyField instruction which will take the final object representation and will try to copy it for the processing according to its target definition, which - for us - is _text_ field of type text_general. Most definitely, not a type that knows what to do with anything but plain strings as an input.
And so, somewhere within Solr bowels, a non-string java.util.Date object gets serialized back into the string format so it could be copied into a text field and then tokenized, lowercased, and so on as per the type definition. And that serialization, obviously, uses a format different from the format used to display the proper date field as part of Solr query. Which is how we get tokens that were neither in the input nor in the output, yet still impacting the search.
And we are not even going to talk about how this impacts the relevancy!
If you liked this Solr puzzle and learned anything from it, please share the original question link via twitter, email, or any other means. You can also share the answer post’s first half, but please do not share this (second half of the answer) post.