Laying out penn treebank output of Stanford parser
I am trying to use Stanford NLP parser for my research and I need to look at the trees it produces for large, complex sentences. I have found several packages for laying out the output as trees, but they are all seem to be targeted at visualizing smaller sentences, suitable for illustrating a point in the published paper.
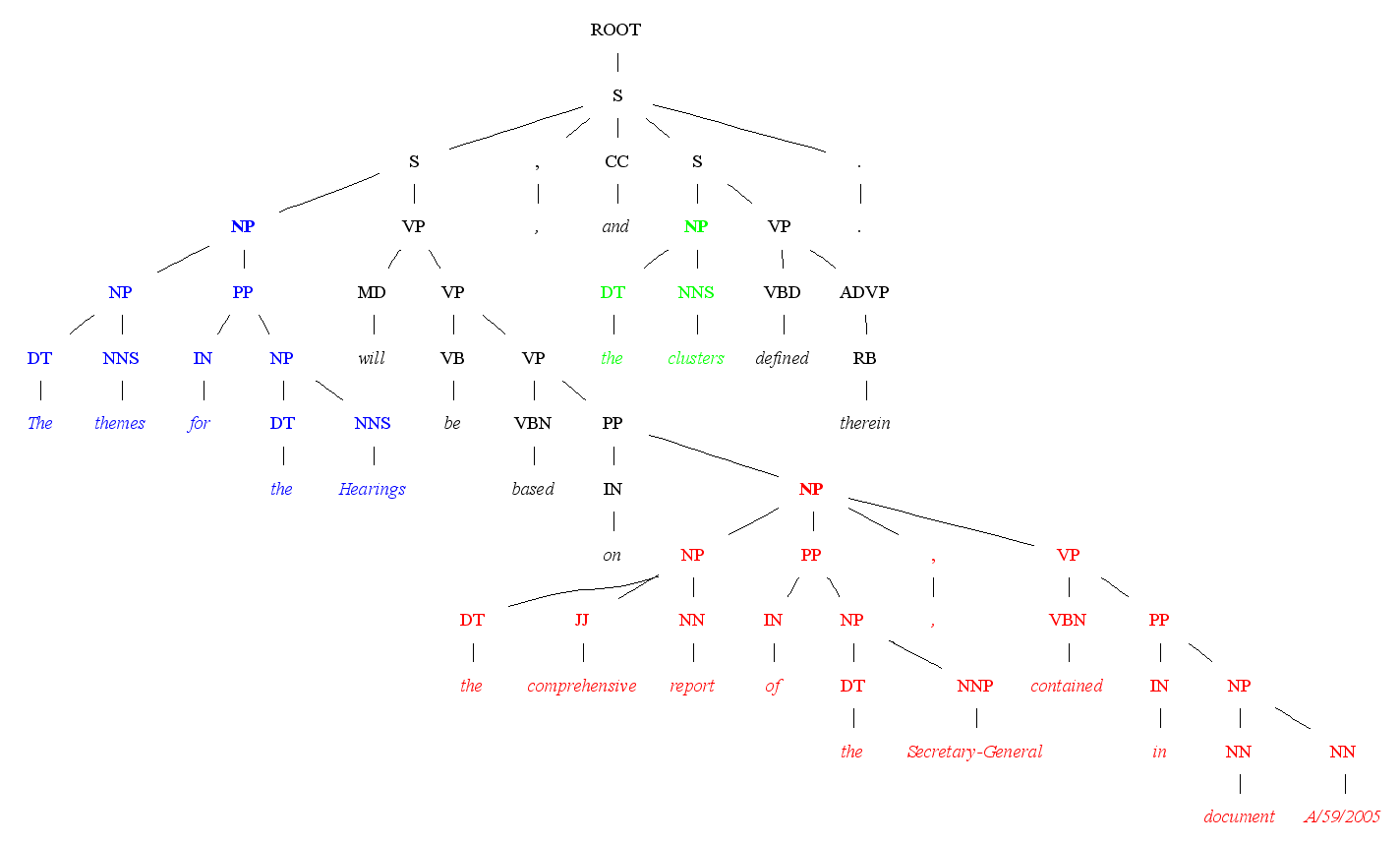
Sample output of Graphviz layout for Stanford Parser’s output
{kind=link}
My trees are large. A sentence of 40 words is an average case, rather than an edge one. So, all of the display packages I have tried cut off large chunks of the tree. It might be possible to tinker with their LaTeX code to produce output that is not cut-off at letter, a4 or even a3 size, but I am not that good with LaTeX yet. And I need to produce this large trees quickly, as I am not even sure whether this parser would be suitable for my needs in the long run.
So, instead, I wrote my own bridging code in Java between penn treebank output of the parser and Graphviz, graph layout software that I use for many layout tasks. The whole implementation was in one file less than 100 lines total and that included the logic to highlight maximum spanning subtrees of a particular element (NounPhrase in this example). Click on the small image to see the full example. Graphviz input file is also available for the curious.
At the moment, it is sufficient to convert to image files. If I ever do convince the parser to understand my 80-word sentences, the resulting trees will probably be large enough to need ZGRViewer.
The Java bridging code is not available yet, as it is very ugly. The secret was in the PennTreeReader’s main() method that showed how to read the parser’s output back in and into Tree form suitable for recursive descent. After that, it was just the code to navigate the tree levels and spit out incredibly easy Graphviz format. I will probably clean the code up a bit over the next couple of weeks and then release it.
If somebody does like the output and wants to see the code sooner, send me an email at alex@thisdomain.